Setting up the site with SSL
I’ve written about my migration from Squarespace to Wordpress earlier this year. One thing I lost with that migration when I went to Wordpress in AWS was having SSL available. While I’m sure Van Hoet will “well actually” me on this, I never could figure out how to set it up ( not that I tried particularly hard ).
The thing is now that I’m hosting on Linode I’m finding some really useful tutorials. This one showed me exactly what I needed to do to get it set up.
Like any good planner I read the how to several times and convinced myself that it was actually relatively straight forward to do and so I started.
Step 1 Creating the cert files
Using this tutorialI was able to create the required certificates to set up SSL. Of course, I ran into an issue when trying to run this command
chmod 400 /etc/ssl/private/example.com.key
I did not have persmision to chmod on that file. After a bit of Googling I found that I can switch to interactive root mode by running the command
sudo -i
It feels a bit dangerous to be able to just do that (I didn’t have to enter a password) but it worked.
Step 2
OK, so the tutorial above got me most(ish) of the way there, but I needed to sign my own certificate. For that I used this tutorial. I followed the directions but kept coming up with an error:
Problem binding to port 443: Could not bind to the IPv4 or IPv6
I rebooted my Linode server. I restarted apache. I googled and I couldn’t find the answer I was looking for.
I wanted to give up, but tried Googling one more time. Finally! An answer so simple it couldn’t work. But then it did.
Stop Apache, run the command to start Apache back up and boom. The error went away and I had a certificate.
However, when I tested the site using SSL LabsI was still getting an error / warning for an untrusted site.
🤦🏻♂️
—
OK ... take 2
I nuked my linode host to start over again.
First things first ... we need to needed to secure my server. Next, we need to set up the server as a LAMP and Linode has this tutorial to walk me through the steps of setting it up.
I ran into an issue when I restarted the Apache service and realized that I had set my host name but hadn’t update the hosts file. No problem though. Just fire up vim and make the additional line:
127.0.0.1 milo
Next, I used this tutorial to create a self signed certificate and this to get the SSL to be set up.
One thing that I expected was that it would just work. After doing some more reading what I realized was that a self signed certificate is useful for internal applications. Once I realized this I decided to not redirect to SSL (i.e. part 443) for my site but instead to just use the ssl certificate it post from Ulysses securely.
Why go to all this trouble just too use a third party application to post to a WordPress site? Because Ulysses is an awesome writing app and I love it. If you’re writing and not using it, I’d give it a try. It really is a nice app.
So really, no good reason. Just that. And, I like to figure stuff out.
OK, so Ulysses is great. But why the need for an SSL certificate? Mostly because when I tried to post to Wordpress from Ulysses without any certificates ( self signed or not ) I would get a warning that my traffic was unencrypted and could be snooped. I figured, better safe than sorry.
Now with the ssl cert all I had to do was trust my self signed certificate and I was set1
- Mostly. I still needed to specify the domain with www otherwise it didn’t work. ↩︎
Installing fonts in Ulysses
One of the people I follow online, Federico Viticci, is an iOS power user, although I would argue that phrase doesn’t really do him justice. He can make the iPad do things that many people can’t get Macs to do.
Recently he posted an article on a new font he is using in Ulysses and I wanted to give it a try. The article says:
Installing custsom fonts in Ulysses for iOS is easy: go to the GitHub page, download each one, and open them in Ulysses (with the share sheet) to install them.
Simple enough, but it wasn’t clicking for me. I kept thinking I had done something wrong. So I thought I’d write up the steps I used so I wouldn’t forget the next time I need to add a new font.
Downloading the Font
- Download the font to somewhere you can get it. I chose to save it to iCloud and use the
Filesapp - Hit Select in the
Filesapp - Click
Share - Select
Open in Ulysses - The custom font is now installed and being used.
Checking the Font:
- Click the ‘A’ in the writing screen (this is the font selector) located in the upper right hand corner of Ulysses

- Notice that the Current font indicates it’s a custom font (in This case iA Writer Duospace:

Not that hard, but there’s no feedback telling you that you have been successful so I wasn’t sure if I had done it or not.
Switching to Linode
Switching to Linode
I’ve been listening to a lot of Talk Python to me lately ... I mean a lot. Recently there was a coupon code for Linode that basically got you four months free with a purchase of a single month, so I thought, ‘what the hell’?
Anyway, I have finally been able to move everything from AWS to Linode for my site and I’m able to publish from my beloved Ulysses.
Initially there was an issue with xmlrpc which I still haven’t fully figured out.
I tried every combination of everything and finally I’m able to publish.
I’m not one to look a gift horse in the mouth so I’ll go ahead and take what I can get. I had meant to document a bit more / better what I had done, but since it basically went from not working to working, I wouldn’t know what to write at this point.
The strangest part is that from the terminal the code I was using to test the issue still returns and xmlrpc faultCode error of -32700 but I’m able to connect now.
I really wish i understood this better, but I’m just happy that I’m able to get it all set and ready to go.
Next task ... set up SSL!
Making Background Images
I'm a big fan of podcasts. I've been listening to them for 4 or 5 years now. One of my favorite Podcast Networks, Relay just had their second anniversary. They offer memberships and after listening to hours and hours of All The Great Shows I decided that I needed to become a member.
One of the awesome perks of Relay membership is a set of Amazing background images.
This is fortuitous as I've been looking for some good backgrounds for my iMac, and so it seemed like a perfect fit.
On my iMac I have several spaces configured. One for Writing, one for Podcast and one for everything else. I wanted to take the backgrounds from Relay and have them on the Writing space and the Podcasting space, but I also wanted to be able to distinguish between them. One thing I could try to do would be to open up an image editor (Like Photoshop, Pixelmater or Acorn) and add text to them one at a time (although I'm sure there is a way to script them) but I decided to see if I could do it using Python.
Turns out, I can.
This code will take the background images from my /Users/Ryan/Relay 5K Backgrounds/ directory and spit them out into a subdirectory called Podcasting
from PIL import Image, ImageStat, ImageFont, ImageDraw
from os import listdir
from os.path import isfile, join
# Declare Text Attributes
TextFontSize = 400
TextFontColor = (128,128,128)
font = ImageFont.truetype("~/Library/Fonts/Inconsolata.otf", TextFontSize)
mypath = '/Users/Ryan/Relay 5K Backgrounds/'
onlyfiles = [f for f in listdir(mypath) if isfile(join(mypath, f))]
onlyfiles.remove('.DS_Store')
rows = len(onlyfiles)
for i in range(rows):
img = Image.open(mypath+onlyfiles[i])
width, height = img.size
draw = ImageDraw.Draw(img)
TextXPos = 0.6 * width
TextYPos = 0.85 * height
draw.text((TextXPos, TextYPos),'Podcasting',TextFontColor,font=font)
draw.text
img.save('/Users/Ryan/Relay 5K Backgrounds/Podcasting/'+onlyfiles[i])
print('/Users/Ryan/Relay 5K Backgrounds/Podcasting/'+onlyfiles[i]+' successfully saved!')
This was great, but it included all of the images, and some of them are really bright. I mean, like really bright.
So I decided to use something I learned while helping my daughter with her Science Project last year and determine the brightness of the images and use only the dark ones.
This lead me to update the code to this:
from PIL import Image, ImageStat, ImageFont, ImageDraw
from os import listdir
from os.path import isfile, join
def brightness01( im_file ):
im = Image.open(im_file).convert('L')
stat = ImageStat.Stat(im)
return stat.mean[0]
# Declare Text Attributes
TextFontSize = 400
TextFontColor = (128,128,128)
font = ImageFont.truetype("~/Library/Fonts/Inconsolata.otf", TextFontSize)
mypath = '/Users/Ryan/Relay 5K Backgrounds/'
onlyfiles = [f for f in listdir(mypath) if isfile(join(mypath, f))]
onlyfiles.remove('.DS_Store')
darkimages = []
rows = len(onlyfiles)
for i in range(rows):
if brightness01(mypath+onlyfiles[i]) <= 65:
darkimages.append(onlyfiles[i])
darkimagesrows = len(darkimages)
for i in range(darkimagesrows):
img = Image.open(mypath+darkimages[i])
width, height = img.size
draw = ImageDraw.Draw(img)
TextXPos = 0.6 * width
TextYPos = 0.85 * height
draw.text((TextXPos, TextYPos),'Podcasting',TextFontColor,font=font)
draw.text
img.save('/Users/Ryan/Relay 5K Backgrounds/Podcasting/'+darkimages[i])
print('/Users/Ryan/Relay 5K Backgrounds/Podcasting/'+darkimages[i]+' successfully saved!')
I also wanted to have backgrounds generated for my Writing space, so I tacked on this code:
for i in range(darkimagesrows):
img = Image.open(mypath+darkimages[i])
width, height = img.size
draw = ImageDraw.Draw(img)
TextXPos = 0.72 * width
TextYPos = 0.85 * height
draw.text((TextXPos, TextYPos),'Writing',TextFontColor,font=font)
draw.text
img.save('/Users/Ryan/Relay 5K Backgrounds/Writing/'+darkimages[i])
print('/Users/Ryan/Relay 5K Backgrounds/Writing/'+darkimages[i]+' successfully saved!')
The print statements at the end of the for loops were so that I could tell that something was actually happening. The images were VERY large (close to 10MB for each one) so the PIL library was taking some time to process the data and I was concerned that something had frozen / stopped working
This was a pretty straightforward project, but it was pretty fun. It allowed me to go from this:

To this:

For the text attributes I had to play around with them for a while until I found the color, font and font size that I liked and looked good (to me).
The Positioning of the text also took a bit of experimentation, but a little trial and error and I was all set.
Also, for the brightness level of 65 I just looked at the images that seemed to work and found a threshold to use. The actual value may vary depending on the look you're doing for.
Presenting Data - Referee Crew Calls in the NFL
One of the great things about computers is their ability to take tabular data and turn them into pictures that are easier to interpret. I'm always amazed when given the opportunity to show data as a picture, more people don't jump at the chance.
For example, this piece on ESPN regarding the difference in officiating crews and their calls has some great data in it regarding how different officiating crews call games.
One thing I find a bit disconcerting is:
- ~~One of the rows is missing data so that row looks 'odd' in the context of the story and makes it look like the writer missed a big thing ... they didn't~~ (it's since been fixed)
- This tabular format is just begging to be displayed as a picture.
Perhaps the issue here is that the author didn't know how to best visualize the data to make his story, but I'm going to help him out.
If we start from the underlying premise that not all officiating crews call games in the same way, we want to see in what ways they differ.
The data below is a reproduction of the table from the article:
REFEREE DEF. OFFSIDE ENCROACH FALSE START NEUTRAL ZONE TOTAL
Triplette, Jeff 39 2 34 6 81 Anderson, Walt 12 2 39 10 63 Blakeman, Clete 13 2 41 7 63 Hussey, John 10 3 42 3 58 Cheffers, Cartlon 22 0 31 3 56 Corrente, Tony 14 1 31 8 54 Steratore, Gene 19 1 29 5 54 Torbert, Ronald 9 4 31 7 51 Allen, Brad 15 1 28 6 50 McAulay, Terry 10 4 23 12 49 Vinovich, Bill 8 7 29 5 49 Morelli, Peter 12 3 24 9 48 Boger, Jerome 11 3 27 6 47 Wrolstad, Craig 9 1 31 5 46 Hochuli, Ed 5 2 33 4 44 Coleman, Walt 9 2 25 4 40 Parry, John 7 5 20 6 38
The author points out:
Jeff Triplette's crew has called a combined 81 such penalties -- 18 more than the next-highest crew and more than twice the amount of two others
The author goes on to talk about his interview with Mike Pereira (who happens to be ~~pimping~~ promoting his new book).
While the table above is helpful it's not an image that you can look at and ask, "Man, what the heck is going on?" There is a visceral aspect to it that says, something is wrong here ... but I can't really be sure about what it is.
Let's sum up the defensive penalties (Defensive Offsides, Encroachment, and Neutral Zone Infractions) and see what the table looks like:
REFEREE DEF Total OFF Total TOTAL
Triplette, Jeff 47 34 81 Anderson, Walt 24 39 63 Blakeman, Clete 22 41 63 Hussey, John 16 42 58 Cheffers, Cartlon 25 31 56 Corrente, Tony 23 31 54 Steratore, Gene 25 29 54 Torbert, Ronald 20 31 51 Allen, Brad 22 28 50 McAulay, Terry 26 23 49 Vinovich, Bill 20 29 49 Morelli, Peter 24 24 48 Boger, Jerome 20 27 47 Wrolstad, Craig 15 31 46 Hochuli, Ed 11 33 44 Coleman, Walt 15 25 40 Parry, John 18 20 38
Now we can see what might actually be going on, but it's still a bit hard for those visual people. If we take this data and then generate a scatter plot we might have a picture to show us the issue. Something like this:
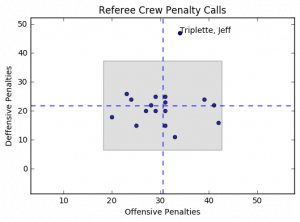
The horizontal dashed blue lines represent the average defensive calls per crew while the vertical dashed blue line represents the average offensive calls per crew. The gray box represents the area containing plus/minus 2 standard deviations from the mean for both offensive and defensive penalty calls.
Notice anything? Yeah, me too. Jeff Triplette's crew is so far out of range for defensive penalties it's like they're watching a different game, or reading from a different play book.
What I'd really like to be able to do is this same analysis but on a game by game basis. I don't think this would really change the way that Jeff Triplette and his crew call games, but it may point out some other inconsistencies that are worth exploring.
Code for this project can be found on my GitHub Repo
Dropbox Files Word Cloud
In one of my previous posts I walked through how I generated a wordcloud based on my most recent 20 tweets. I though it would be neat to do this for my Dropbox file names as well. just to see if I could.
When I first tried to do it (as previously stated, the Twitter Word Cloud post was the first python script I wrote) I ran into some difficulties. I didn't really understand what I was doing (although I still don't really understand, I at least have a vague idea of what the heck I'm doing now).
The script isn't much different than the Twitter word cloud. The only real differences are:
- the way in which the
wordsvariable is being populated - the mask that I'm using to display the cloud
In order to go get the information from the file system I use the glob library:
import glob
The next lines have not changed
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
from scipy.misc import imread
Instead of writing to a 'tweets' file I'm looping through the files, splitting them at the / character and getting the last item (i.e. the file name) and appending it to the list f:
f = []
for filename in glob.glob('/Users/Ryan/Dropbox/Ryan/**/*', recursive=True):
f.append(filename.split('/')[-1])
The rest of the script generates the image and saves it to my Dropbox Account. Again, instead of using a Twitter logo, I'm using a Cloud image I found here
words = ' '
for line in f:
words= words + line
stopwords = {'https'}
logomask = imread('mask-cloud.png')
wordcloud = WordCloud(
font_path='/Users/Ryan/Library/Fonts/Inconsolata.otf',
stopwords=STOPWORDS.union(stopwords),
background_color='white',
mask = logomask,
max_words=1000,
width=1800,
height=1400
).generate(words)
plt.imshow(wordcloud.recolor(color_func=None, random_state=3))
plt.axis('off')
plt.savefig('/Users/Ryan/Dropbox/Ryan/Post Images/dropbox_wordcloud.png', dpi=300)
plt.show()
And we get this:

Installing the osmnx package for Python
I read about a cool gis package for Python and decided I wanted to play around with it. This post isn't about any of the things I've learned about the package, it's so I can remember how I installed it so I can do it again if I need to. The package is described by it's author in his post
To install osmnx I needed to do the following:
-
Install Home Brew if it's not already installed by running this command (as an administrator) in the
terminal:/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" -
Use Home Brew to install the
spatialindexdependency. From theterminal(again as an administrator):brew install spatialindex -
In python run pip to install
rtree:pip install rtree -
In python run pip to install
osmnxpip install osmnx
I did this on my 2014 iMac but didn't document the process. This lead to a problem when I tried to run some code on my 2012 MacBook Pro.
Step 3 may not be required, but I'm not sure and I don't want to not have it written down and then wonder why I can't get osmnx to install in 3 years when I try again!
Remember, you're not going to remember what you did, so you need to write it down!
Twitter Word Cloud
As previously mentioned I'm a bit of a Twitter user. One of the things that I came across, actually the first python project I did, was writing code to create a word cloud based on the most recent 20 posts of my Twitter feed.
I used a post by Sebastian Raschka and a post on TechTrek.io as guides and was able to generate the word cloud pretty easily.
As usual, we import the need libraries:
import tweepy, json, random
from tweepy import OAuthHandler
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
from scipy.misc import imread
The code below allows access to my feed using secret keys from my twitter account. They have been removed from the post so that my twitter account doesn't stop being mine:
consumer_key = consumer_key
consumer_secret = consumer_secret
access_token = access_token
access_secret = access_secret
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
Next I open a file called tweets and write to it the tweets (referred to in the for loop as status) and encode with utf-8. If you don't do the following error is thrown: TypeError: a bytes-like object is required, not 'str'. And who wants a TypeError to be thrown?
f = open('tweets', 'wb')
for status in api.user_timeline():
f.write(api.get_status(status.id).text.encode("utf-8"))
f.close()
Now I'm ready to do something with the tweets that I collected. I read the file into a variable called words
words=' '
count =0
f = open('tweets', 'rb')
for line in f:
words= words + line.decode("utf-8")
f.close
Next, we start on constructing the word cloud itself. We declare words that we want to ignore (in this case https is ignored, otherwise it would count the protocol of links that I've been tweeting).
stopwords = {'https', 'co', 'RT'}
Read in the twitter bird to act as a mask
logomask = imread('twitter_mask.png')
Finally, generate the wordcloud, plot it and save the image:
wordcloud = WordCloud(
font_path='/Users/Ryan/Library/Fonts/Inconsolata.otf',
stopwords=STOPWORDS.union(stopwords),
background_color='white',
mask = logomask,
max_words=500,
width=1800,
height=1400
).generate(words)
plt.imshow(wordcloud.recolor(color_func=None, random_state=3))
plt.axis('off')
plt.savefig('./Twitter Word Cloud - '+time.strftime("%Y%m%d")+'.png', dpi=300)
plt.show()
The second to last line generates a dynamically named file based on the date so that I can do this again and save the image without needing to do too much thinking.
Full Code can be found on my GitHub Report
My Twitter Word Cloud as of today looks like this:

I think it will be fun to post this image every once in a while, so as I remember, I'll run the script again and update the Word Cloud!
Home, End, PgUp, PgDn ... BBEdit Preferences
As I've been writing up my posts for the last couple of days I've been using the amazing macOS Text Editor BBEdit. One of the things that has been tripping me up though are my 'Windows' tendencies on the keyboard. Specifically, my muscle memory of the use and behavior of the Home, End, PgUp and PgDn keys. The default behavior for these keys in BBEdit are not what I needed (nor wanted). I lived with it for a couple of days figuring I'd get used to it and that would be that.
While driving home from work today I was listening to ATP Episode 196 and their Post-Show discussion of the recent departure of Sal Soghoian who was the Project Manager for the macOS automation. I'm not sure why, but suddenly it clicked with me that I could probably change the behavior of the keys through the Preferences for the Keyboard (either system wide, or just in the Application).
When I got home I fired up BBEdit and jumped into the preferences and saw this:

I made a couple of changes, and now the keys that I use to navigate through the text editor are now how I want them to be:

Nothing too fancy, or anything, but goodness, does it feel right to have the keys work the way I need them to.
Pitching Stats and Python
I'm an avid Twitter user, mostly as a replacement RSS feeder, but also because I can't stand Facebook and this allows me to learn about really important world events when I need to and to just stay isolated with my head in the sand when I don't. It's perfect for me.
One of the people I follow on Twitter is Dr. Drang who is an Engineer of some kind by training. He also appears to be a fan of baseball and posted an analysis of Jake Arrieata's pitching over the course of the 2016 MLB season (through September 22 at least).
When I first read it I hadn't done too much with Python, and while I found the results interesting, I wasn't sure what any of the code was doing (not really anyway).
Since I had just spent the last couple of days learning more about BeautifulSoup specifically and Python in general I thought I'd try to do two things:
- Update the data used by Dr. Drang
- Try to generalize it for any pitcher
Dr. Drang uses a flat csv file for his analysis and I wanted to use BeautifulSoup to scrape the data from ESPN directly.
OK, I know how to do that (sort of ¯\(ツ)/¯)
First things first, import your libraries:
import pandas as pd
from functools import partial
import requests
import re
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
from datetime import datetime, date
from time import strptime
The next two lines I ~~stole~~ borrowed directly from Dr. Drang's post. The first line is to force the plot output to be inline with the code entered in the terminal. The second he explains as such:
The odd ones are the
rcParamscall, which makes the inline graphs bigger than the tiny Jupyter default, and the functools import, which will help us create ERAs over small portions of the season.
I'm not using Jupyter I'm using Rodeo as my IDE but I kept them all the same:
%matplotlib inline
plt.rcParams['figure.figsize'] = (12,9)
In the next section I use BeautifulSoup to scrape the data I want from ESPN:
url = 'http://www.espn.com/mlb/player/gamelog/_/id/30145/jake-arrieta'
r = requests.get(url)
year = 2016
date_pitched = []
full_ip = []
part_ip = []
earned_runs = []
tables = BeautifulSoup(r.text, 'lxml').find_all('table', class_='tablehead mod-player-stats')
for table in tables:
for row in table.find_all('tr'): # Remove header
columns = row.find_all('td')
try:
if re.match('[a-zA-Z]{3}\s', columns[0].text) is not None:
date_pitched.append(
date(
year
, strptime(columns[0].text.split(' ')[0], '%b').tm_mon
, int(columns[0].text.split(' ')[1])
)
)
full_ip.append(str(columns[3].text).split('.')[0])
part_ip.append(str(columns[3].text).split('.')[1])
earned_runs.append(columns[6].text)
except Exception as e:
pass
This is basically a rehash of what I did for my Passer scraping (here, here, and here).
This proved a useful starting point, but unlike the NFL data on ESPN which has pre- and regular season breaks, the MLB data on ESPN has monthly breaks, like this:
Regular Season Games through October 2, 2016
DATE
Oct 1
Monthly Totals
DATE
Sep 24
Sep 19
Sep 14
Sep 9
Monthly Totals
DATE
Jun 26
Jun 20
Jun 15
Jun 10
Jun 4
Monthly Totals
DATE
May 29
May 23
May 17
May 12
May 7
May 1
Monthly Totals
DATE
Apr 26
Apr 21
Apr 15
Apr 9
Apr 4
Monthly Totals
However, all I wanted was the lines that correspond to columns[0].text with actual dates like 'Apr 21'.
In reviewing how the dates were being displayed it was basically '%b %D', i.e. May 12, Jun 4, etc. This is great because it means I want 3 letters and then a space and nothing else. Turns out, Regular Expressions are great for stuff like this!
After a bit of Googling I got what I was looking for:
re.match('[a-zA-Z]{3}\s', columns[0].text)
To get my regular expression and then just add an if in front and call it good!
The only issue was that as I ran it in testing, I kept getting no return data. What I didn't realize is that returns a NoneType when it's false. Enter more Googling and I see that in order for the if to work I have to add the is not None which leads to results that I wanted:
Oct 22
Oct 16
Oct 13
Oct 11
Oct 7
Oct 1
Sep 24
Sep 19
Sep 14
Sep 9
Jun 26
Jun 20
Jun 15
Jun 10
Jun 4
May 29
May 23
May 17
May 12
May 7
May 1
Apr 26
Apr 21
Apr 15
Apr 9
Apr 4
The next part of the transformation is to convert to a date so I can sort on it (and display it properly) later.
With all of the data I need, I put the columns into a Dictionary:
dic = {'date': date_pitched, 'Full_IP': full_ip, 'Partial_IP': part_ip, 'ER': earned_runs}
and then into a DataFrame:
games = pd.DataFrame(dic)
and apply some manipulations to the DataFrame:
games = games.sort_values(['date'], ascending=[True])
games[['Full_IP','Partial_IP', 'ER']] = games[['Full_IP','Partial_IP', 'ER']].apply(pd.to_numeric)
Now to apply some Baseball math to get the Earned Run Average:
games['IP'] = games.Full_IP + games.Partial_IP/3
games['GERA'] = games.ER/games.IP*9
games['CIP'] = games.IP.cumsum()
games['CER'] = games.ER.cumsum()
games['ERA'] = games.CER/games.CIP*9
In the next part of Dr. Drang's post he writes a custom function to help create moving averages. It looks like this:
def rera(games, row):
if row.name+1 < games:
ip = df.IP[:row.name+1].sum()
er = df.ER[:row.name+1].sum()
else:
ip = df.IP[row.name+1-games:row.name+1].sum()
er = df.ER[row.name+1-games:row.name+1].sum()
return er/ip*9
The only problem with it is I called my DataFrame games, not df. Simple enough, I'll just replace df with games and call it a day, right? Nope:
def rera(games, row):
if row.name+1 < games:
ip = games.IP[:row.name+1].sum()
er = games.ER[:row.name+1].sum()
else:
ip = games.IP[row.name+1-games:row.name+1].sum()
er = games.ER[row.name+1-games:row.name+1].sum()
return er/ip*9
When I try to run the code I get errors. Lots of them. This is because while i made sure to update the DataFrame name to be correct I overlooked that the function was using a parameter called games and Python got a bit confused about what was what.
OK, round two, replace the parameter games with games_t:
def rera(games_t, row):
if row.name+1 < games_t:
ip = games.IP[:row.name+1].sum()
er = games.ER[:row.name+1].sum()
else:
ip = games.IP[row.name+1-games_t:row.name+1].sum()
er = games.ER[row.name+1-games_t:row.name+1].sum()
return er/ip*9
No more errors! Now we calculate the 3- and 4-game moving averages:
era4 = partial(rera, 4)
era3 = partial(rera,3)
and then add them to the DataFrame:
games['ERA4'] = games.apply(era4, axis=1)
games['ERA3'] = games.apply(era3, axis=1)
And print out a pretty graph:
plt.plot_date(games.date, games.ERA3, '-b', lw=2)
plt.plot_date(games.date, games.ERA4, '-r', lw=2)
plt.plot_date(games.date, games.GERA, '.k', ms=10)
plt.plot_date(games.date, games.ERA, '--k', lw=2)
plt.show()
Dr. Drang focused on Jake Arrieta (he is a Chicago guy after all), but I thought it was be interested to look at the Graphs for Arrieta and the top 5 finishers in the NL Cy Young Voting (because Clayton Kershaw was 5th place and I'm a Dodgers guy).
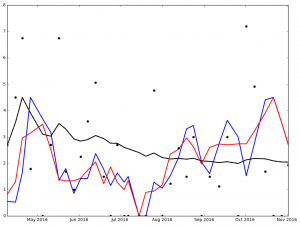
Here is the graph for Jake Arrieata:
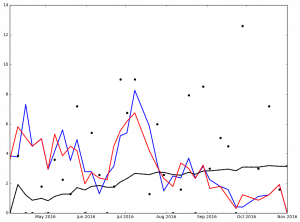
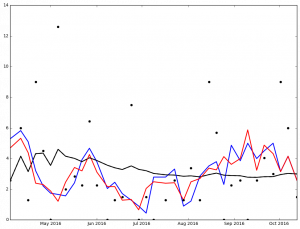
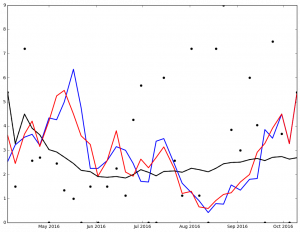
And here are the graphs for the top 5 finishers in Ascending order in the 2016 NL Cy Young voting:
Max Scherzer winner of the 2016 NL Cy Young Award
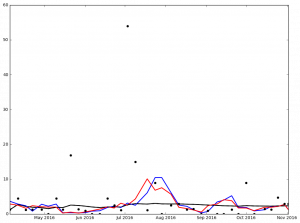
{kind=link}
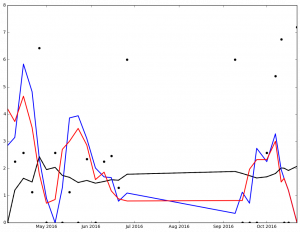
I've not spent much time analyzing the data, but I'm sure that it says something. At the very least, it got me to wonder, 'How many 0 ER games did each pitcher pitch?'
I also noticed that the stats include the playoffs (which I wasn't intending). Another thing to look at later.
Legend:
- Black Dot - ERA on Date of Game
- Black Solid Line - Cumulative ERA
- Blue Solid Line - 3-game trailing average ERA
- Red Solid Line - 4-game trailing average ERA
Full code can be found on my Github Repo
Page 12 / 13